When the training data looks like this plot
[Plot 1]
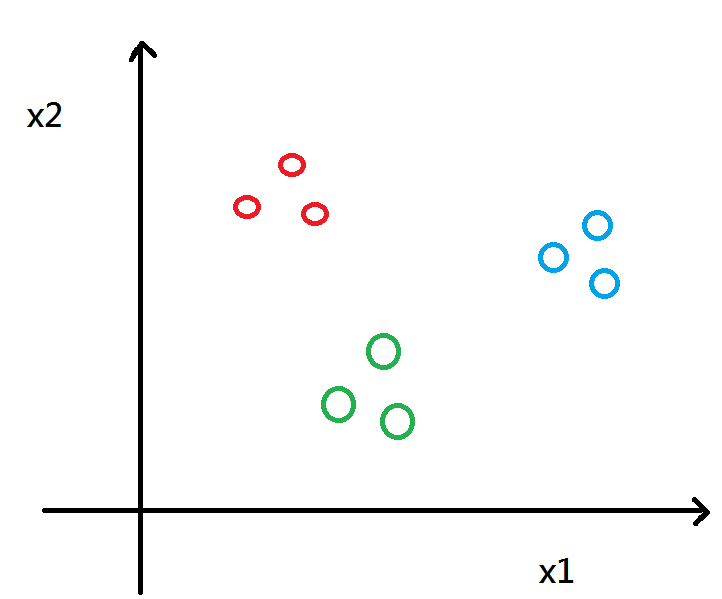
We can use one v.s all classification help us.
First, we let red circle be the positive and the circle fill in purple as negative, then we may have the boundary $h_{\theta}^{(1)}(x)$ like this.
[Plot 2]

Second we let the green circle be the positive and the circle fill in purple as negative, then we can have the boundary $h_{\theta}^{(2)}(x)$ like this.
[Plot 3]

In the final, do the same thing, we can get the last boundary $h_{\theta}^{(3)}(x)$ like this.
[Plot 4]

Concretely, we fit a classifier $h_{\theta}^{(i)}(x)$ and estimate what is the probability that y = i class, or $ P(y = i | x ; \theta)$
So, to wrap up, if we want to classify an k-class problem, we need to train k classifier to solve the problem.
No comments:
Post a Comment